
Machine learning research aims to learn representations that enable effective downstream task performance. A growing subfield seeks to interpret these representations’ roles in model behaviors or modify them to enhance alignment, interpretability, or generalization. Similarly, neuroscience examines neural representations and their behavioral correlations. Both fields focus on understanding or improving system computations, abstract behavior patterns on tasks, and their implementations. The relationship between representation and computation is complex and needs to be more straightforward.
Highly over-parameterized deep networks often generalize well despite their capacity for memorization, suggesting an implicit inductive bias towards simplicity in their architectures and gradient-based learning dynamics. Networks biased towards simpler functions facilitate easier learning of simpler features, which can impact internal representations even for complex features. Representational biases favor simple, common features influenced by factors such as feature prevalence and output position in transformers. Shortcut learning and disentangled representation research highlight how these biases affect network behavior and generalization.
In this work, DeepMind researchers investigate dissociations between representation and computation by creating datasets that match the computational roles of features while manipulating their properties. Various deep learning architectures are trained to compute multiple abstract features from inputs. Results show systematic biases in feature representation based on properties like feature complexity, learning order, and feature distribution. Simpler or earlier-learned features are more strongly represented than complex or later-learned ones. These biases are influenced by architectures, optimizers, and training regimes, such as transformers favoring features decoded earlier in the output sequence.
Their approach involves training networks to classify multiple features either through separate output units (e.g., MLP) or as a sequence (e.g., Transformer). The datasets are constructed to ensure statistical independence among features, with models achieving high accuracy (>95%) on held-out test sets, confirming the correct computation of features. The study investigates how properties such as feature complexity, prevalence, and position in the output sequence affect feature representation. Families of training datasets are created to systematically manipulate these properties, with corresponding validation and test datasets ensuring expected generalization.
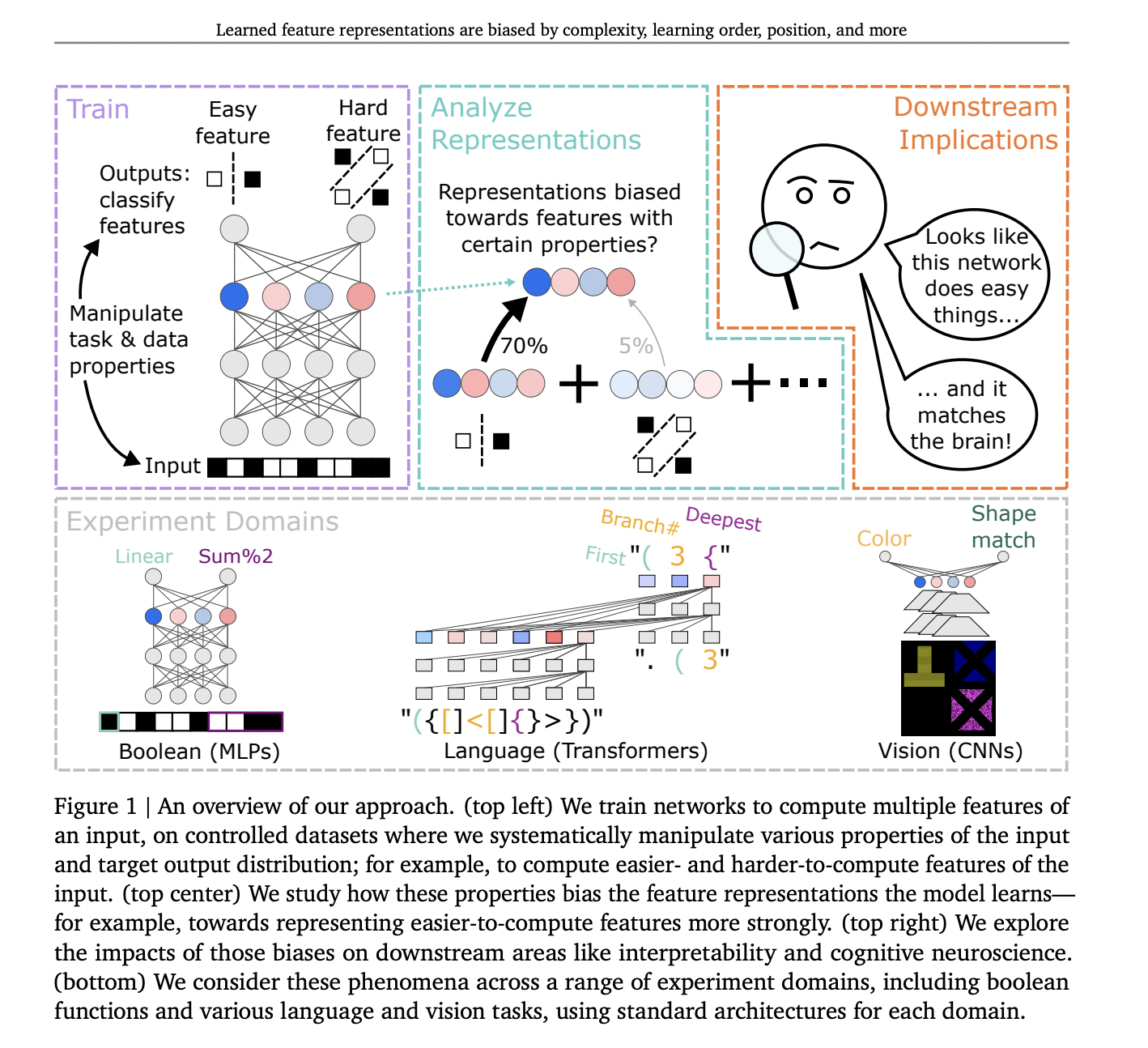
Training various deep learning architectures to compute multiple abstract features reveals systematic biases in feature representation. These biases depend on extraneous properties like feature complexity, learning order, and feature distribution. Simpler or earlier-learned features are represented more strongly than complex or later-learned ones, even if all are learned equally well. Architectures, optimizers, and training regimes, such as transformers, also influence these biases. These findings characterize the inductive biases of gradient-based representation learning and highlight challenges in disentangling extraneous biases from computationally important aspects for interpretability and comparison with brain representations.
In this work, researchers trained deep learning models to compute multiple input features, revealing substantial biases in their representations. These biases depend on feature properties like complexity, learning order, dataset prevalence, and output sequence position. Representational biases may relate to implicit inductive biases in deep learning. Practically, these biases pose challenges for interpreting learned representations and comparing them across different systems in machine learning, cognitive science, and neuroscience.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Source link




