MIPRO: A Novel Optimizer that Outperforms Baselines on Five of Six Diverse Language Model LM Programs Using a Best-in-Class Open-Source Model (Llama-3-8B) by 12.9% accuracy
 by 12.9% accuracy")
Language Models (LMs) have significantly advanced complex NLP tasks through sophisticated prompting techniques and multi-stage pipelines. However, designing these LM Programs relies heavily on manual “prompt engineering,” a time-consuming process of crafting lengthy prompts through trial and error. This approach faces challenges, particularly in multi-stage LM programs where gold labels or evaluation metrics for individual LM calls are often lacking. The absence of these metrics makes it difficult to assess and optimize each stage independently, hindering the overall efficiency and effectiveness of LM programs. As a result, there’s a pressing need for more systematic and automated approaches to optimize multi-stage LM pipelines.
Various approaches have been introduced to optimize LM programs, including gradient-guided search, reranking brute force search, evolutionary algorithms, and prompting other LMs. Some studies explored reinforcement learning for prompt optimization, focusing on word-level or phrase-level edits. Notable attempts include DSPy, which introduced a programming model for expressing and optimizing LM programs, and an approach modeling joint prompt optimization for stacked LLM calls as variational inference. However, these methods often fall short in addressing the complexities of multi-stage LM programs, particularly when dealing with arbitrary numbers of modules and diverse LM architectures. Existing approaches are limited by their focus on specific types of edits, reliance on log probabilities, or inability to optimize free-form instructions for sophisticated multi-prompt pipelines. This leaves a gap for a more flexible and comprehensive optimization approach that can handle complex, multi-stage LM pipelines without restrictive assumptions.
The researchers propose a robust approach to optimize prompts for LM programs, focusing on maximizing downstream metrics without requiring module-level labels or gradients. Their method, called MIPRO, factorizes the optimization problem into refining free-form instructions and few-shot demonstrations for each module in the LM program. MIPRO employs several innovative strategies to overccome the challenges of prompt optimization in multi-stage pipelines. These include program- and data-aware techniques for generating effective instructions, a stochastic mini-batch evaluation function to learn a surrogate model of the objective and a meta-optimization procedure that improves the LM’s proposal construction over time. This comprehensive approach enables MIPRO to navigate the complexities of credit assignment across modules and craft task-grounded instructions.
The researchers present a detailed architecture for optimizing multi-stage LM programs, MIPRO. This method focuses on optimizing free-form instructions and few-shot demonstrations for each module in the program. It addresses key challenges through several innovative strategies. For the proposal problem, it employs bootstrapping demonstrations, grounding techniques, and learning to propose. These approaches help generate task-relevant instructions and demonstrations. For credit assignment across modules, MIPRO explores greedy, surrogate, and history-based methods. The surrogate model uses a Bayesian approach to predict the quality of variable combinations, while the history-based method utilizes past evaluations to inform future proposals. It also incorporates a stochastic mini-batch evaluation function and a meta-optimization procedure to refine proposal generation over time. This comprehensive architecture enables MIPRO to efficiently navigate the complex optimization landscape of multi-stage LM programs.
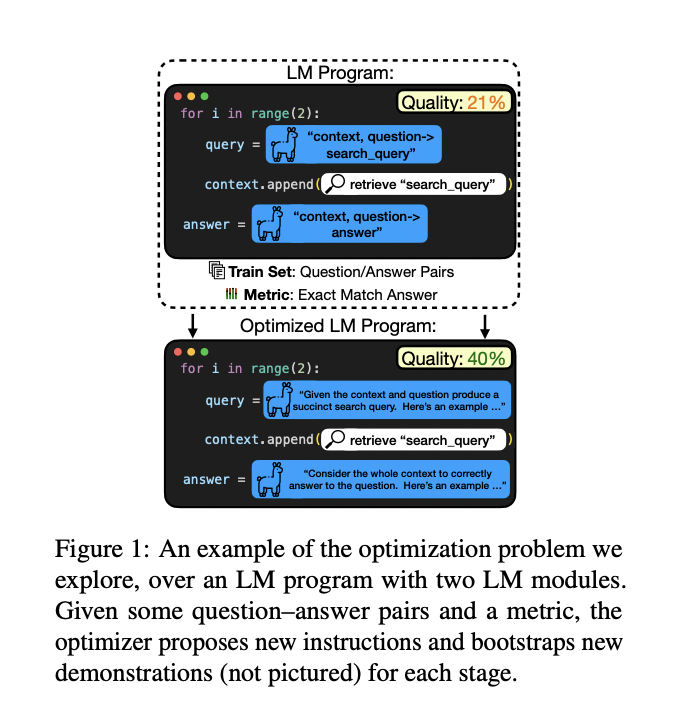
The results of the MIPRO optimization approach reveal several key insights. Optimizing bootstrapped demonstrations as few-shot examples proved crucial for achieving the best performance in most tasks. MIPRO, which optimizes both instructions and few-shot examples, generally yielded the best overall performance across tasks. Instruction optimization was found to be particularly important for tasks with conditional rules that are not immediately obvious to the LM and are not easily expressed through a limited number of few-shot examples. Grounding techniques were generally helpful for instruction proposals, although the best proposal strategy varied by task.
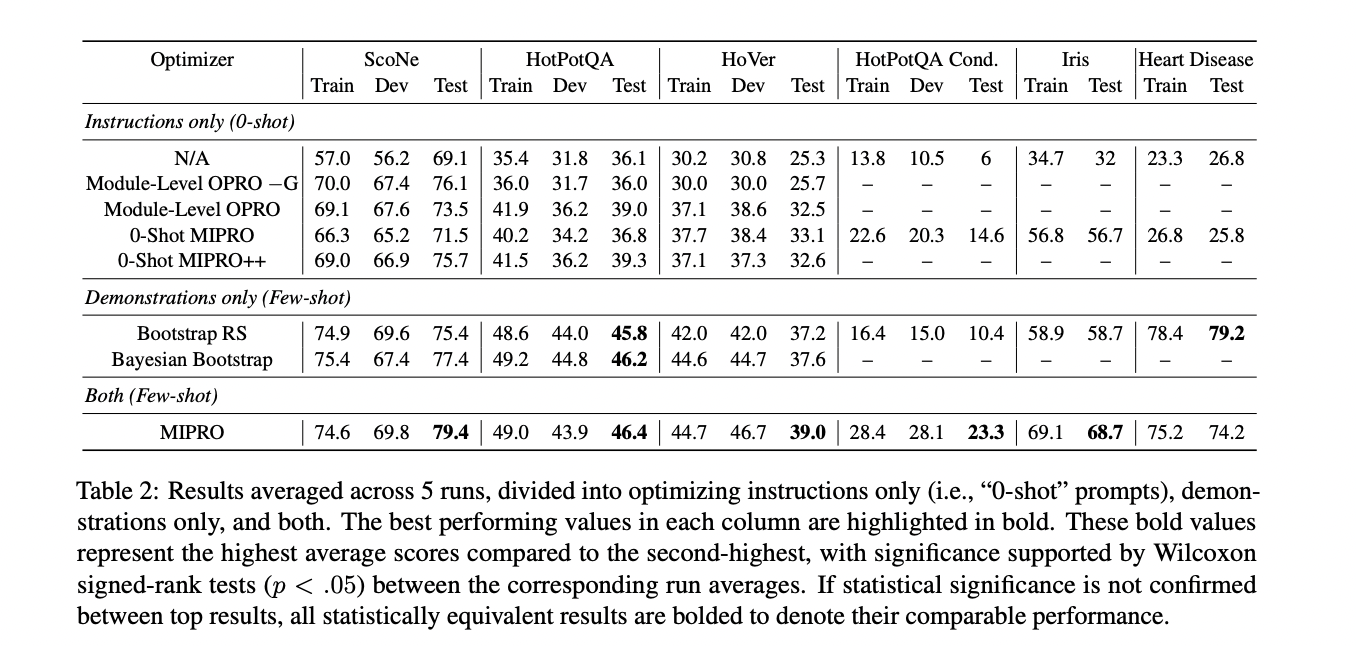
This study formalizes LM program optimization as a prompt search problem, addressing the challenges of proposal generation and credit assignment. By exploring various strategies for diverse tasks, the research demonstrates that optimizing few-shot demonstrations is highly effective, while instruction optimization is crucial for complex tasks. The study ultimately finds that jointly optimizing both demonstrations and instructions yields the best results, paving the way for more efficient and powerful multi-stage LM programs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
🚀 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Source link



