
In recent years, image generation has made significant progress due to advancements in both transformers and diffusion models. Similar to trends in generative language models, many modern image generation models now use standard image tokenizers and de-tokenizers. Despite showing great success in image generation, image tokenizers encounter fundamental limitations due to the way they are designed. These tokenizers are based on the assumption that the latent space should retain a 2D structure to maintain a direct mapping for locations between the latent tokens and image patches.
This paper discusses three existing methods in the realm of image processing and understanding. Firstly, Image Tokenization has been a fundamental approach since the early days of deep learning, utilizing autoencoders to compress high-dimensional images into low-dimensional latent representations and then decode them back. The second approach is Tokenization for Image Understanding, which is used for image understanding tasks such as image classification, object detection, segmentation, and multimodal large language models (MLLMs). Last is the Image Generation, in which methods have evolved from sampling variational autoencoders (VAEs) to utilizing generative adversarial networks (GANs), diffusion models, and autoregressive models.
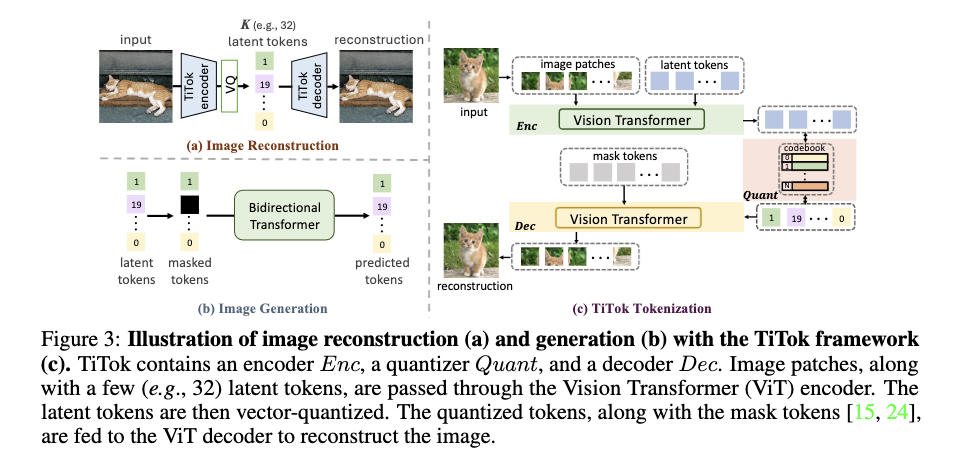
Researchers from Technical University Munich and ByteDance have proposed an innovative approach that tokenizes images into 1D latent sequences, named Transformer-based 1-Dimensional Tokenizer (TiTok). TiTok consists of a Vision Transformer (ViT) encoder, a ViT decoder, and a vector quantizer, similar to typical Vector-Quantized (VQ) model designs. During the tokenization phase, the image is divided into patches, which are then flattened and combined into a 1D sequence of latent tokens. After the ViT encoder processes the image features, the resulting latent tokens form the image’s latent representation.
Along with the Image Generation task using a tokenizer, TiTok also shows its efficiency in image generation by using a typical pipeline. For the generation framework, MaskGIT is used because of its simplicity and effectiveness, which allows for training a MaskGIT model by simply replacing its VQGAN tokenizer with TiTok model. The process begins by pre-tokenizing the image into 1D discrete tokens, and a random ratio of the latent tokens is replaced with mask tokens at each training step. After that, a bidirectional transformer takes this masked token sequence as input and predicts the corresponding discrete token IDs for the masked tokens.
TiTok provides a more compact way for latent representation, making it much more efficient than traditional methods. For example, a 256 × 256 × 3 image can be reduced to just 32 discrete tokens, compared to the 256 or 1024 tokens used by earlier techniques. Using the same generator framework, TiTok achieves a gFID score of 1.97, outperforming the MaskGIT baseline by 4.21 on the ImageNet 256 × 256 benchmark. TiTok’s advantages are even more significant at higher resolutions. On the ImageNet 512 × 512 benchmark, TiTok not only outperforms the leading diffusion model DiT-XL/2 but also reduces the number of image tokens by 64 times, resulting in a generation process that is 410 times faster.
In this paper, researchers have introduced an innovative method that tokenizes images into 1D latent sequences called TiTok. It can be used for reconstructing and generating natural images. A compact formulation is provided to tokenize an image into a 1D latent sequence. The proposed method can represent an image with 8 to 64 times fewer tokens than the commonly used 2D tokenizers. Moreover, the compact 1D tokens enhance the training and inference speed of the generation model, as well as obtain a competitive FID on the ImageNet benchmarks. The future direction will focus on more efficient image representation and generation models with 1D image tokenization.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
Source link




 Privacy")