MIT Researchers Propose Cross-Layer Attention (CLA): A Modification to the Transformer Architecture that Reduces the Size of the Key-Value KV Cache by Sharing KV Activations Across Layers
: A Modification to the Transformer Architecture that Reduces the Size of the Key-Value KV Cache by Sharing KV Activations Across Layers")
The memory footprint of the key-value (KV) cache can be a bottleneck when serving large language models (LLMs), as it scales proportionally with both sequence length and batch size. This overhead limits batch sizes for long sequences and necessitates costly techniques like offloading when on-device memory is scarce. Furthermore, the ability to persistently store and retrieve KV caches over extended periods is desirable to avoid redundant computations. However, the size of the KV cache directly impacts the cost and feasibility of storing and retrieving these persistent caches. As LLM applications increasingly demand longer input sequences, the memory requirements of the KV cache have become a critical consideration in designing efficient transformer-based language models.
Traditionally, Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) have been employed to reduce the KV cache size. The original transformer architecture employed Multi-Head Attention (MHA), where each query head attends to the keys and values produced by a distinct key/value head. To reduce the overhead of storing and accessing the KV cache during decoding, MQA organizes the query heads into groups, with each group sharing a single key/value head. GQA generalizes this idea by allowing varying numbers of groups. Since the KV cache size scales only with the number of distinct key/value heads, MQA and GQA effectively reduce the storage overhead. However, these techniques have limitations in terms of achievable memory reduction.

In this paper, researchers from MIT have developed a method called Cross-Layer Attention (CLA) that extends the idea of key/value head sharing. A diagrammatic view of it is presented in Figure 1. CLA enables the sharing of key and value heads not only within a layer but also across adjacent layers. By computing key/value projections for only a subset of layers and allowing other layers to reuse KV activations from previous layers, CLA achieves a significant reduction in the KV cache memory footprint. The reduction factor is equal to the sharing factor or slightly less if the sharing factor does not evenly divide the number of layers.
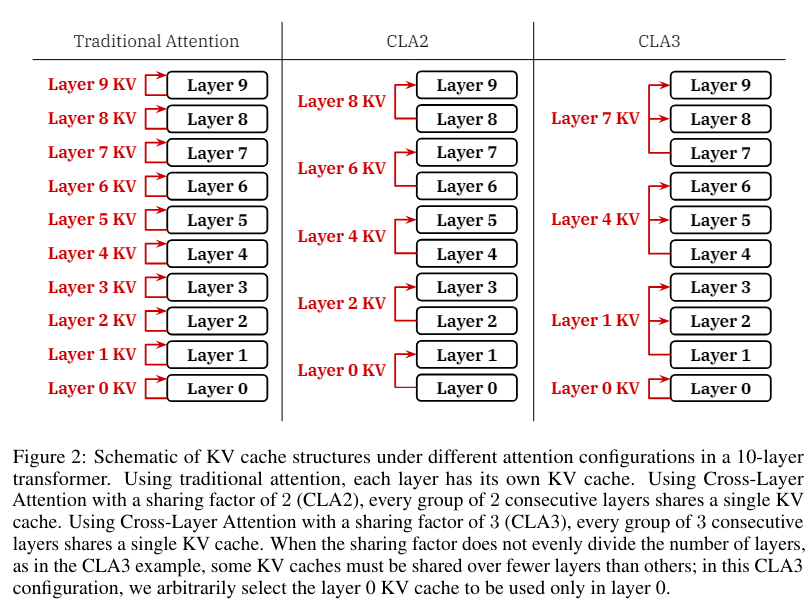
CLA is orthogonal to MQA and GQA, meaning it can be combined with either technique. The sharing factor determines the number of layers that share the output of each KV projection, governing different CLA configurations. For example as shown in Figure 2, CLA2 shares each KV projection among a pair of adjacent layers, while CLA3 shares it among a group of three layers.
Let’s now see some benefits of CLA: It reduces the memory footprint of intermediate KV activation tensors materialized during training, although this reduction is typically small compared to the model’s hidden states and MLP activations. CLA is fully compatible with standard tensor parallelism techniques for sharding model weights across multiple accelerators. In the presence of pipeline parallelism, either different layers sharing a KV cache must be kept in the same pipeline stage, or KV activations must be communicated between pipeline stages. By reducing the total number of key/value projection blocks, CLA slightly decreases the number of parameters in the model and the number of FLOPs required during forward or backward passes. Importantly, CLA enables larger batch sizes and longer KV cache persistence times, which have the potential to improve inference latency in the context of a full LLM serving stack. However, unlike MQA and GQA, CLA has no direct effect on the memory bandwidth consumed by the attention mechanism in each decoding step or the latency of the core attention computation during decoding.
To assess CLA’s efficacy, the researchers trained transformer-based language models from scratch at the 1 billion and 3 billion parameter scales. Their experiments aimed to answer questions like what accuracy/memory tradeoffs are possible using CLA, how it compares to plain GQA or MQA, how it interacts with these techniques, what CLA configurations perform best given a fixed memory budget, and whether the effects are consistent across scales.
The key findings of the experiment are as follows: CLA enables favorable accuracy/memory tradeoffs compared to plain GQA or MQA. A sharing factor of 2 (CLA2) was more effective than other sharing factors in the experimental regime. CLA was consistently effective when combined with MQA to decrease KV cache storage. CLA models benefited from training with higher learning rates than comparable non-CLA models. The benefits were consistent across both 1B- and 3B-parameter scales.
Quantitatively, MQA-CLA2 consistently achieved the lowest validation perplexity (within 0.01 points) for a given KV cache memory budget and model size. At both 1B and 3B scales, for MQA models with typical head sizes of 64 and 128, applying CLA2 yielded a 2× KV cache reduction while incurring, at worst, a very modest (less than 1% change) degradation in perplexity, and in some cases, even improving perplexity. The researchers recommend the MQA-CLA2 recipe to practitioners as a conservative change to existing MQA architectures that deliver substantial memory overhead reductions with relatively little risk.
The researchers suspect that the LLMs that will gain the most from CLA are those with extremely long sequences, such as models with long-term memory or those using Landmark Attention, which renders attention over long contexts more feasible. However, they leave end-to-end inference efficiency evaluations of large, long-context models employing CLA as an interesting problem for future work.
In conclusion, Cross-Layer Attention (CLA) emerges as an effective method for reducing the KV cache memory storage footprint of transformer models by a factor of 2× with roughly equal perplexity compared to existing techniques. Based on extensive experimental evaluation against well-tuned baselines at both the 1B- and 3B-parameter scales, CLA advances the Pareto frontier for memory-efficient transformers, making it a promising solution for memory-constrained applications of large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Source link


